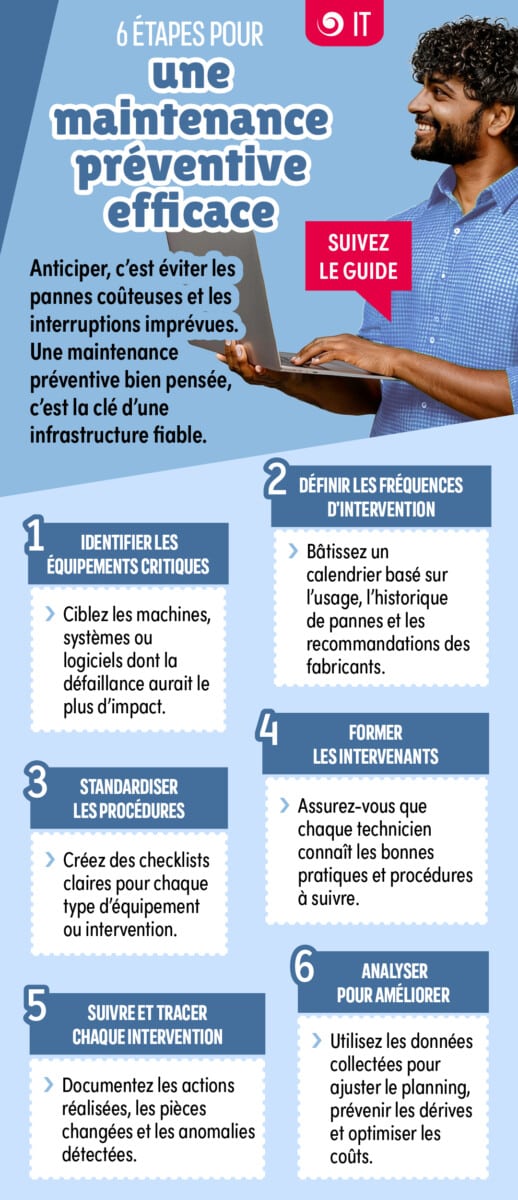
Las averías informáticas salen caras: interrupciones del servicio, pérdida de productividad, riesgos de seguridad e insatisfacción de los usuarios. Un mantenimiento preventivo bien organizado permite anticiparse a los incidentes antes de que afecten a la actividad. A continuación, te presentamos seis buenas prácticas que debes adoptar para reforzar la fiabilidad y el rendimiento de tu infraestructura.

1. Identificar los equipos y servicios críticos
No todos los componentes de una infraestructura tienen el mismo nivel de importancia. El primer paso consiste en identificar los activos esenciales para el funcionamiento de la empresa:
- Servidores de producción
- Equipos de red (conmutadores, enrutadores, cortafuegos)
- Soluciones de almacenamiento
- Aplicaciones críticas para el negocio
- Servicios en la nube
- Herramientas de copia de seguridad y seguridad
El objetivo es determinar qué elementos, en caso de no estar disponibles, tendrían las consecuencias más graves para la actividad. Este análisis permite priorizar las tareas de mantenimiento y asignar los recursos de manera eficaz.
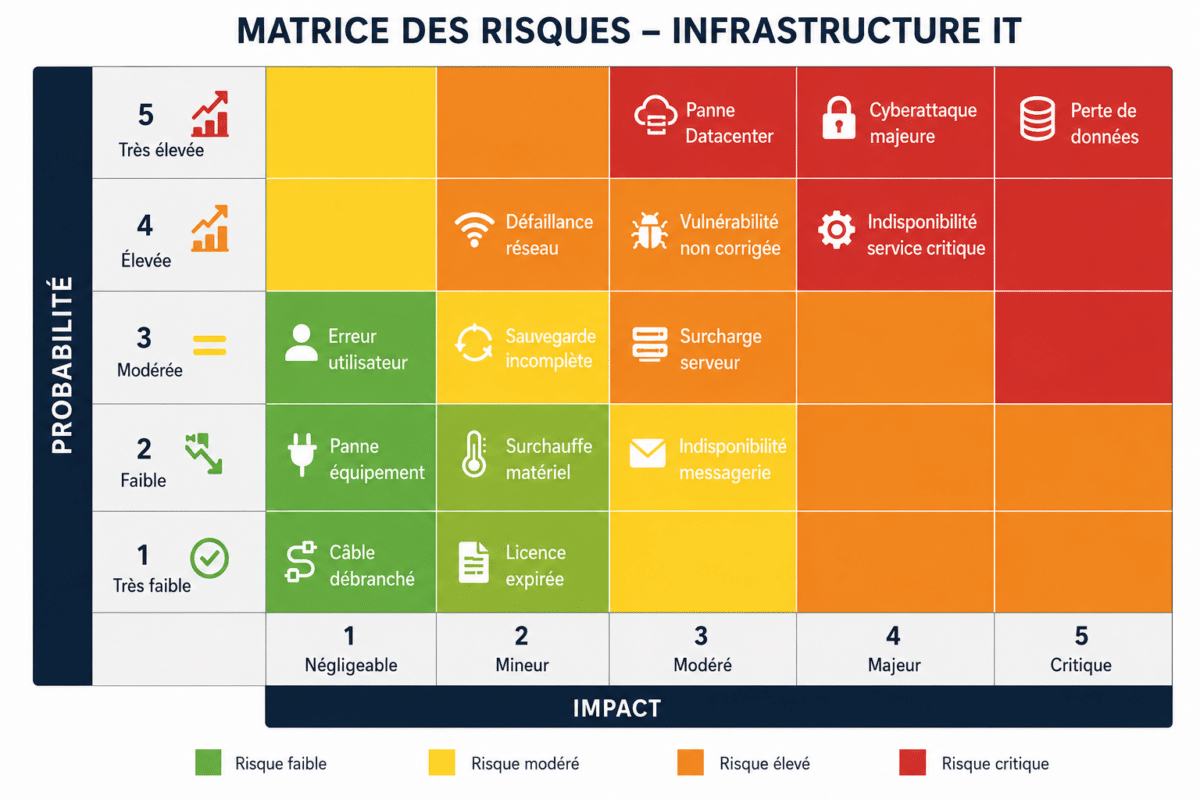
Un buen hábito: elaborar una matriz de criticidad (matriz de riesgos) evaluando el impacto en el negocio y la probabilidad de fallo de cada equipo.
2. Establecer un calendario de mantenimiento estructurado
Un mantenimiento eficaz se basa en la regularidad. Establezca una periodicidad de intervención adecuada para cada componente:
- Comprobación diaria de las copias de seguridad
- Revisión semanal de las alertas del sistema
- Actualización mensual de parches de seguridad
- Auditoría trimestral del rendimiento
- Prueba anual del plan de recuperación de la actividad (PRA)
El calendario también debe incluir las ventanas de mantenimiento para minimizar el impacto en los usuarios y las operaciones.
3. Estandarizar los procedimientos de intervención
Los errores humanos se encuentran entre las principales causas de los incidentes informáticos. Para reducirlos, documenta con precisión las operaciones recurrentes:
- Actualización de los servidores
- Sustitución de un equipo de red
- Gestión de copias de seguridad
- Revisión de los registros del sistema
- Comprobación de los sistemas de seguridad
Los procedimientos estandarizados garantizan una ejecución uniforme, incluso cuando interviene un técnico diferente.
4. Formar continuamente a los equipos técnicos
Las infraestructuras evolucionan rápidamente: nuevas tecnologías en la nube, ciberseguridad, virtualización, automatización, inteligencia artificial, etc. Un equipo que no se forme periódicamente corre el riesgo de pasar por alto señales débiles o de aplicar métodos obsoletos.
La formación debe abarcar:
- Buenas prácticas de seguridad
- Los procedimientos internos
- Las nuevas versiones de las herramientas utilizadas
- Los escenarios de gestión de crisis
- Técnicas de diagnóstico avanzadas
Un equipo competente detecta las anomalías con mayor rapidez y reduce considerablemente los tiempos de interrupción.
5. Garantizar la trazabilidad completa de las operaciones
Cada intervención debe registrarse en una herramienta de seguimiento o en una plataforma ITSM para mantener un historial fiable:
- Fecha y hora de la intervención
- Técnico responsable
- Equipo afectado
- Acciones llevadas a cabo
- Piezas o componentes sustituidos
- Resultados observados
Esta documentación facilita el análisis de los incidentes recurrentes y mejora la transmisión de conocimientos entre los equipos.
Imprescindible: centralizar la información en una CMDB (base de datos de gestión de la configuración) o en una herramienta de gestión documental accesible para todos los implicados.
6. Aprovechar los datos para anticipar incidentes
El mantenimiento preventivo moderno ya no se limita a las revisiones periódicas. Gracias a las herramientas de supervisión y monitorización, es posible detectar los primeros indicios de una avería:
- Aumento anormal de la carga de la CPU
- Saturación progresiva del almacenamiento
- Aumento del tráfico de red
- Temperaturas inusuales en los equipos
- Aumento de los errores del sistema
El análisis de estos datos permite pasar de un mantenimiento preventivo a un enfoque predictivo, en el que las intervenciones se activan incluso antes de que se produzca la avería.
Herramientas de uso habitual: Centreon, Zabbix, PRTG, Grafana, Datadog, Microsoft System Center