IT-storingen brengen hoge kosten met zich mee: onderbrekingen van de dienstverlening, productiviteitsverlies, veiligheidsrisico’s en ontevredenheid bij de gebruikers. Met goed georganiseerd preventief onderhoud kunt u incidenten voorkomen voordat ze de bedrijfsvoering beïnvloeden. Hieronder volgen zes aanbevolen werkwijzen om de betrouwbaarheid en prestaties van uw infrastructuur te verbeteren.

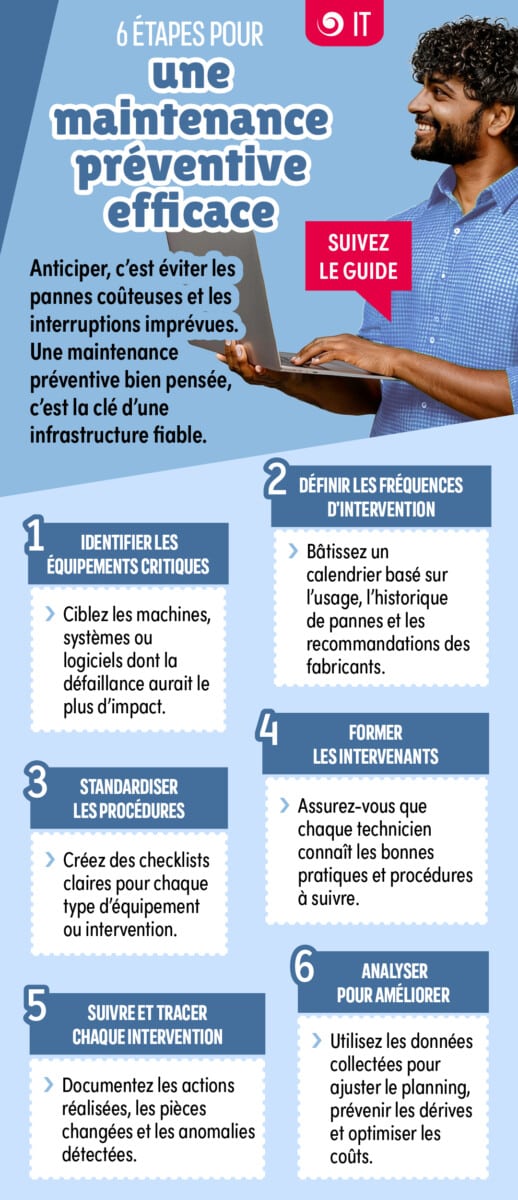
1. Kritieke apparatuur en diensten in kaart brengen
Niet alle onderdelen van een infrastructuur zijn even belangrijk. De eerste stap bestaat erin de activa in kaart te brengen die essentieel zijn voor de bedrijfsvoering:
- Productieservers
- Netwerkapparatuur (switches, routers, firewalls)
- Opslagoplossingen
- Kritieke bedrijfstoepassingen
- Clouddiensten
- Back-up- en beveiligingstools
Het doel is om vast te stellen welke onderdelen, indien ze niet beschikbaar zijn, de grootste gevolgen zouden hebben voor de bedrijfsvoering. Deze analyse maakt het mogelijk om onderhoudswerkzaamheden te prioriteren en middelen efficiënt in te zetten.
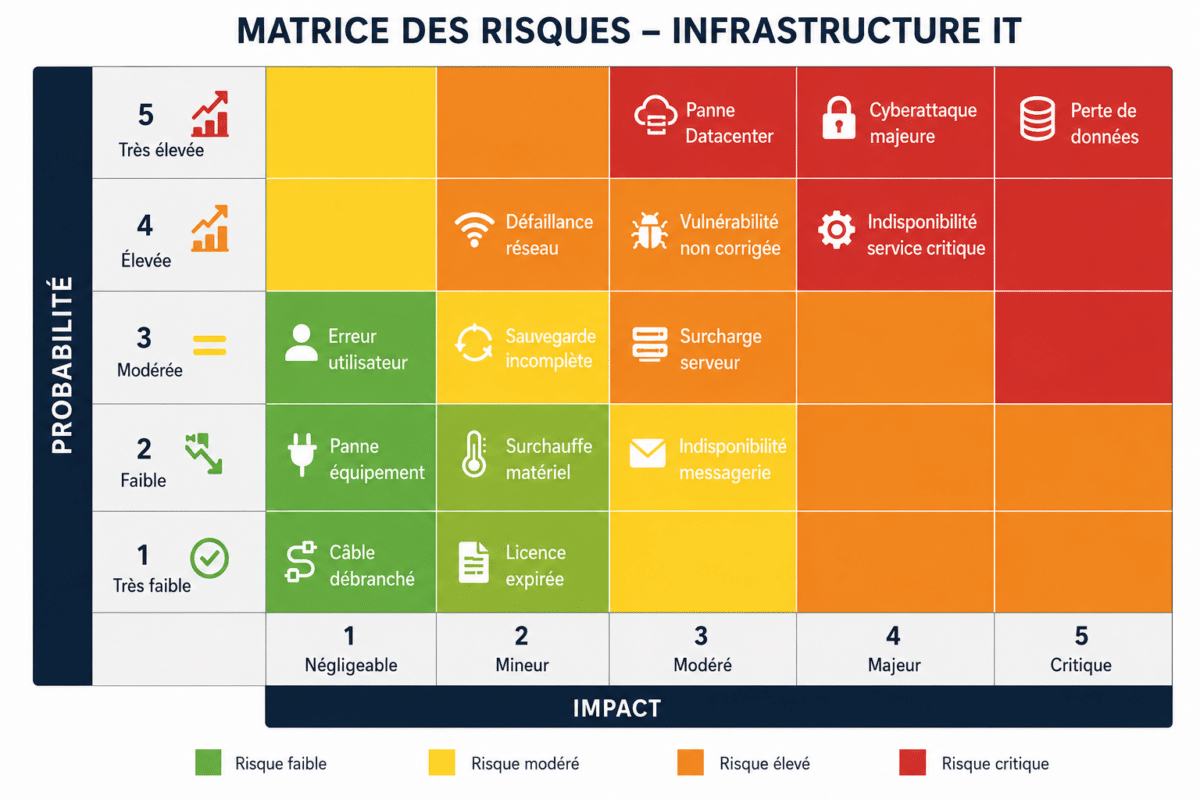
Een goede gewoonte: een kriticiteitsmatrix (risicomatrix) opstellen door de impact op de bedrijfsvoering en de kans op uitval van elke apparatuur te beoordelen.
2. Een gestructureerd onderhoudsschema opstellen
Effectief onderhoud is afhankelijk van regelmaat. Stel voor elk onderdeel een passende onderhoudsfrequentie vast:
- Dagelijkse controle van de back-ups
- Wekelijkse controle van systeemwaarschuwingen
- Maandelijkse update van beveiligingspatches
- Driemaandelijkse prestatiebeoordeling
- Jaarlijkse test van het noodherstelplan (NHP)
In de planning moet ook rekening worden gehouden met onderhoudsperiodes om de gevolgen voor de gebruikers en de bedrijfsvoering tot een minimum te beperken.
3. De interventieprocedures standaardiseren
Menselijke fouten behoren tot de belangrijkste oorzaken van IT-incidenten. Om deze te beperken, dient u terugkerende handelingen nauwkeurig te documenteren:
- Servers bijwerken
- Vervanging van netwerkapparatuur
- Beheer van back-ups
- Controle van systeemlogboeken
- Controle van de beveiligingssystemen
Gestandaardiseerde procedures zorgen voor een consistente uitvoering, zelfs wanneer er een andere technicus aan het werk is.
4. De technische teams voortdurend bijscholen
De infrastructuur verandert snel: nieuwe cloudtechnologieën, cyberbeveiliging, virtualisatie, automatisering, kunstmatige intelligentie, enzovoort. Een team dat niet regelmatig bijscholing volgt, loopt het risico dat het subtiele signalen over het hoofd ziet of verouderde methoden blijft toepassen.
De opleiding moet het volgende omvatten:
- Beste praktijken op het gebied van veiligheid
- Interne procedures
- De nieuwe versies van de gebruikte tools
- Scenario's voor crisisbeheersing
- Geavanceerde diagnostische technieken
Een bekwaam team signaleert afwijkingen sneller en zorgt ervoor dat de uitvaltijd aanzienlijk wordt verkort.
5. Zorgen voor volledige traceerbaarheid van de processen
Elke interventie moet worden geregistreerd in een trackingtool of een ITSM-platform om een betrouwbare historiek bij te houden:
- Datum en tijdstip van de ingreep
- Betrokken technicus
- Betrokken apparatuur
- Uitgevoerde acties
- Vervangen onderdelen of componenten
- Waargenomen resultaten
Deze documentatie vergemakkelijkt de analyse van terugkerende incidenten en bevordert de kennisoverdracht binnen de teams.
Onmisbaar: de informatie centraliseren in een CMDB (Configuration Management Database) of een documentbeheersysteem dat voor alle betrokkenen toegankelijk is.
6. Gegevens gebruiken om incidenten te voorkomen
Modern preventief onderhoud beperkt zich niet langer tot periodieke controles. Dankzij supervisie- en monitoringtools is het mogelijk om de eerste tekenen van een storing op te sporen:
- Abnormale stijging van de CPU-belasting
- Geleidelijke verzadiging van de opslagcapaciteit
- Toename van het netwerkverkeer
- Ongewone temperaturen in de apparatuur
- Toename van systeemfouten
Door deze gegevens te analyseren kan men overschakelen van preventief onderhoud naar een voorspellende aanpak, waarbij ingrepen worden uitgevoerd nog voordat er een storing optreedt.
Veelgebruikte hulpmiddelen: Centreon, Zabbix, PRTG, Grafana, Datadog, Microsoft System Center