Les pannes informatiques coûtent cher : interruptions de service, perte de productivité, risques de sécurité et insatisfaction des utilisateurs. Une maintenance préventive bien organisée permet d’anticiper les incidents avant qu’ils n’impactent l’activité. Voici les six bonnes pratiques à adopter pour renforcer la fiabilité et la performance de votre infrastructure.

1. Identifier les équipements et services critiques
Tous les composants d’une infrastructure n’ont pas le même niveau d’importance. La première étape consiste à cartographier les actifs essentiels au fonctionnement de l’entreprise :
- Serveurs de production
- Équipements réseau (switchs, routeurs, pare-feux)
- Solutions de stockage
- Applications métiers critiques
- Services cloud
- Outils de sauvegarde et de sécurité
L’objectif est de déterminer les éléments dont une indisponibilité aurait les conséquences les plus importantes sur l’activité. Cette analyse permet de prioriser les actions de maintenance et d’allouer les ressources de manière efficace.
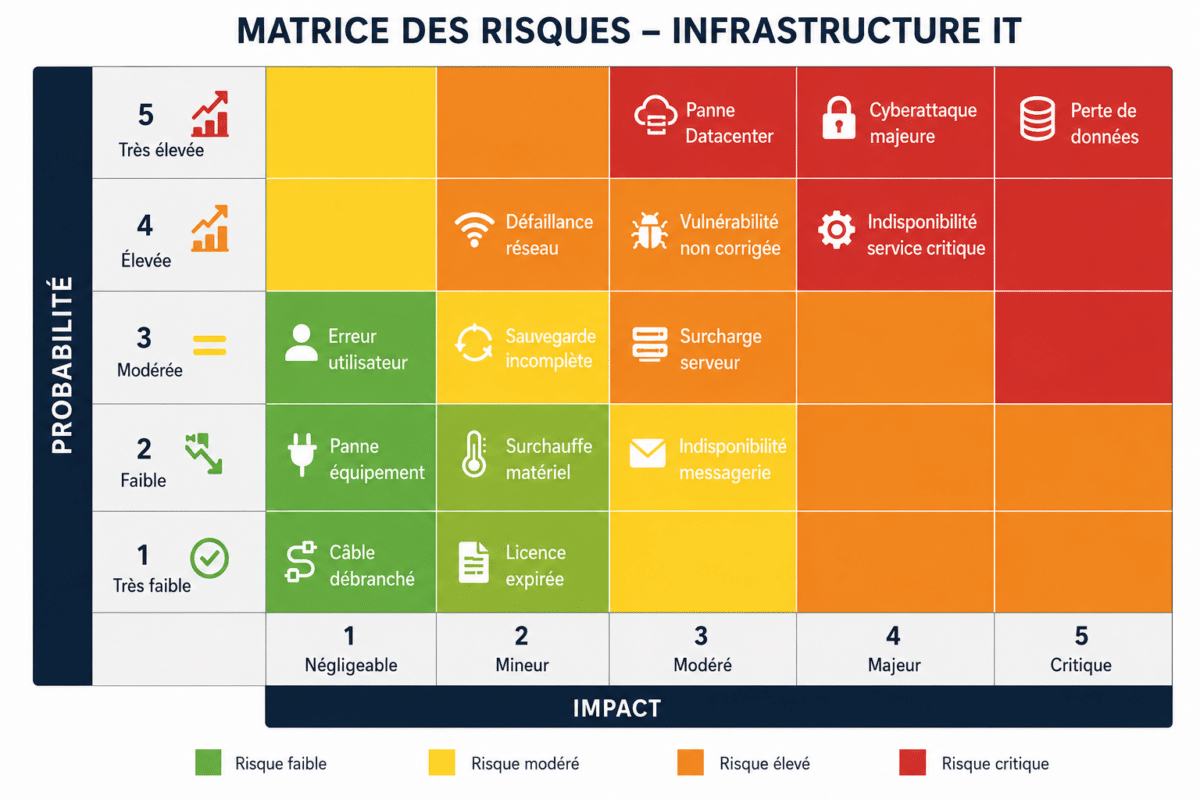
Bon réflexe : établir une matrice de criticité (matrice des risques) en évaluant l’impact métier et la probabilité de défaillance de chaque équipement.
2. Mettre en place un calendrier de maintenance structuré
Une maintenance efficace repose sur la régularité. Définissez des fréquences d’intervention adaptées à chaque composant :
- Vérification quotidienne des sauvegardes
- Contrôle hebdomadaire des alertes système
- Mise à jour mensuelle des correctifs de sécurité
- Audit trimestriel des performances
- Test annuel du plan de reprise d’activité (PRA)
Le calendrier doit également intégrer les fenêtres de maintenance afin de limiter l’impact sur les utilisateurs et les opérations.
3. Standardiser les procédures d’intervention
Les erreurs humaines figurent parmi les principales causes d’incidents IT. Pour les limiter, documentez précisément les opérations récurrentes :
- Mise à jour des serveurs
- Remplacement d’un équipement réseau
- Gestion des sauvegardes
- Contrôle des journaux système
- Vérification des systèmes de sécurité
Des procédures standardisées garantissent une exécution homogène, même lorsqu’un technicien différent intervient.
4. Former continuellement les équipes techniques
Les infrastructures évoluent rapidement : nouvelles technologies cloud, cybersécurité, virtualisation, automatisation, intelligence artificielle, etc. Une équipe qui ne se forme pas régulièrement risque de manquer des signaux faibles ou d’appliquer des méthodes obsolètes.
La formation doit couvrir :
- Les bonnes pratiques de sécurité
- Les procédures internes
- Les nouvelles versions des outils utilisés
- Les scénarios de gestion de crise
- Les techniques de diagnostic avancées
Une équipe compétente détecte plus rapidement les anomalies et réduit significativement les temps d’interruption.
5. Assurer une traçabilité complète des opérations
Chaque intervention doit être enregistrée dans un outil de suivi ou une plateforme ITSM afin de conserver un historique fiable :
- Date et heure de l’intervention
- Technicien concerné
- Équipement impacté
- Actions réalisées
- Pièces ou composants remplacés
- Résultats observés
Cette documentation facilite l’analyse des incidents récurrents et améliore la transmission des connaissances au sein des équipes.
Indispensable : centraliser les informations dans une CMDB (Configuration Management Database) ou un outil de gestion documentaire accessible à tous les intervenants.
6. Exploiter les données pour anticiper les incidents
La maintenance préventive moderne ne se limite plus aux contrôles périodiques. Grâce aux outils de supervision et de monitoring, il est possible de détecter les signes avant-coureurs d’une défaillance :
- Augmentation anormale de la charge CPU
- Saturation progressive du stockage
- Hausse du trafic réseau
- Températures inhabituelles dans les équipements
- Multiplication des erreurs système
L’analyse de ces données permet de passer d’une maintenance préventive à une logique prédictive, où les interventions sont déclenchées avant même que la panne ne survienne.
Outils couramment utilisés : Centreon, Zabbix, PRTG, Grafana, Datadog, Microsoft System Center